- A+
最近,reddit用户deepfakes发布了一系列采用深度学习技术合成的AV,影片中的女主角可以被替换为任意女星。据该用户称,大家只要掌握基本的机器学习技术用GTX1080渲染数小时就可获得想要的视频。
去年开始就在国外网站上比较火的项目了,国外网站Reddit有版块专门探讨此类内容,不过随着各大网站强烈的反对,女星XX片的交流版块最终还是被关闭了,当时就有不少人制作了换脸视频,其中大部分是替换了XX片的女主角。
国内网友利用网络主播的视频,采用Deepfakes技术,生成了唐嫣、 杨幂、刘亦菲、范冰冰等明星的演唱片段,基本可以以假乱真了。
在这篇文章中,我将会介绍DeepFakes这项AI换脸技术的功能和原理,并且阐述其有发展前途的应用领域。
本文目录
什么是DeepFakes?
DeepFakes实际上是一种人脸交换技术,顾名思义,也就是在图像或视频中把一张脸替换成另一张脸。事实上,人脸交换技术在电影制作领域已经不是个新鲜词了,但是之前电影视频中的人脸交换非常复杂,专业的视频剪辑师和CGI专家需要花费大量时间和精力才能完成视频中的人脸交换。
DeepFakes的出现可以说是人脸交换技术的一个突破。利用DeepFakes技术,你只需要一个GPU和一些训练数据,就能够制作出以假乱真的换脸视频。
这可以说是一个非常了不起的突破了,因为你只需要把上百张人物的样图输入至一个算法,就能完成人脸交换,制作出非常逼真的视频效果。就算你是个对视频剪辑一窍不通的外行,也能做到这样。
DeepFakes的出现还意味着我们可以在视频中进行大规模的“换脸”。我们大多数人都曾经把自己的照片上传到网络上,因此,我们大多数人的脸都能够轻易地被替换到一些视频中,成为视频的“主角”。不得不说,这是件非常可怕的事情,但这也并不那么值得恐慌,毕竟我们大家早已接受了“照骗”(照片造假)。
DeepFakes能够让你在没有任何技巧的情况下完成这样的“面部定制”,但DeepFakes可不是“面部定制”。
DeepFakes究竟能做些什么?
在讨论如何使用DeepFakes之前,我想先解决这样的问题:DeepFakes究竟能够做些什么?它的技术原理是什么?

为了了解其工作原理,我选了Jimmy Fallon和John Oliver主持的节目视频作为分析案例。Jimmy Fallon和John Oliver是两位非常受欢迎的晚间节目主持人,网络上有大量他们的节目视频。这些视频的亮度变化差不多,主持人在视频中的动作和姿势也很相似,这些相似性有利于降低分析的受干扰程度。但视频同时又存在大量的变化(例如主持人嘴唇的变化),这样又能够保证分析的趣味性。
很幸运,我找到了一个包含了原始DeepFakes编码和很多DeepFakes改进版编码的GitHub。这个GitHub使用起来相当简单,但是目前还处于训练数据收集和准备的阶段。
为了让我们的分析实验更简单,我写了一个能够直接在YouTube视频上运行的脚本,这样一来,数据的收集和预处理工作就变得轻松多了,视频转换也只需一步就能完成。点击此处查看我的GitHub报告,看看我是如何轻松地制作下面这个视频的(我还分享了我的模型数据)。
简单来说,这个脚本需要你给需要进行人脸交换的人各自准备一个YouTube视频集,然后运行命令来对视频进行预处理(从YouTube下载视频、提取各个视频的帧、找出视频中的人脸)和训练,并将其转换为音频和可调整大小的选项等。
从Jimmy Fallon到John Oliver的“换脸”结果
下面的视频是经过了大约30000张(Jimmy和Oliver每人各约15000张)图片的模型训练制作完成的,我从6-8个时长分别在3-5分钟的YouTube视频中过滤掉了那些不含Jimmy和Oliver的脸的帧,留下了含有他们的脸的一些帧——每个视频每秒大约20帧。以上这些操作全部都是自动完成的,我只是提供了一个YouTube视频集。
在NVIDIA GTX 1080 TI的GPU上训练的总时长大约是72小时。训练时间主要与训练的GPU有关,而下载视频并将其划分成帧的时间与I/O相关,这两步是可以同时进行的。
尽管我截取到的Jimmy和Oliver的人脸图片有几万张,但是达成完美的人脸交换大概只需300张图片。我选择“视频截人脸”的方式是因为,视频中出现的人脸很多,从视频中截取人脸图片非常方便,但如果在网上找这么多人脸图片可就麻烦得多了。
为了避免GIF动画的文件过大,下面的这张图片被设置成了低分辨率。下面的YouTube视频分辨率更高、声音更大。
https://giphy.com/gifs/fo23NLu9hCqAZYi4Eh?utm_source=iframe&utm_medium=embed&utm_campaign=Embeds&utm_term=https%3A%2F%2Fwww.kdnuggets.com%2F2018%2F03%2Fexploring-deepfakes.html
视频中的Oliver正在演唱Iggy Azalea的《fancy》,视频中虽然有麦克风的干扰,但算法最后呈现的效果还算不错。
https://giphy.com/gifs/3JNJb4qjDaCeMDvrlZ?utm_source=iframe&utm_medium=embed&utm_campaign=Embeds&utm_term=https%3A%2F%2Fwww.kdnuggets.com%2F2018%2F03%2Fexploring-deepfakes.html
这个视频是Oliver正在主持“吉米秀”(Jimmy主持的晚间节目)。我们发现视频中Oliver的脸上多了一副眼镜,但他的头发和脸型基本没有影响,整个视频看上去非常自然和谐,几乎看不出换脸的痕迹。
到目前为止,DeepFakes还没到完美的程度,但其呈现出的效果已经相当令人满意了。关键是我事先并没有对视频做过任何改动,全是算法的功劳——算法通过观察大量的图片数据,学会制作出这样以假乱真的换脸视频。你一定也觉得非常神奇吧?那么接下来,让我们一起看看DeepFakes究竟是怎么做到的。
DeepFakes的技术原理
DeepFakes的核心是一个“自动编码器”,这个“自动编码器”实际上是一个深度神经网络,它能够接收数据输入,并将其压缩成一个小的编码,然后从这个编码中重新生成原始的输入数据。
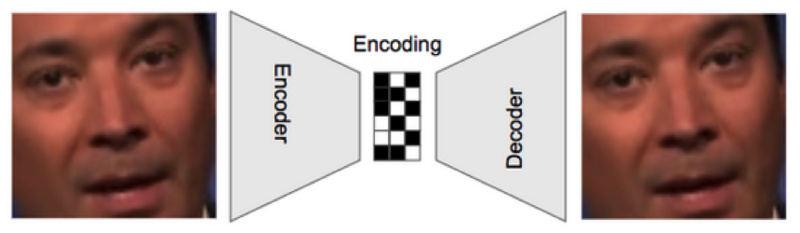
在这个标准的自动编码器设置中,网络将尝试学习创建一个编码,从中网络能够重新生成输入的原始图片。只要有足够多的图像数据,网络就能学会创建这种编码。
DeepFakes让一个编码器把一个人脸压缩成一个代码和两个解码器,一个将其还原成人物A(Fallon),另一个还原成人物B(Oliver)。下面的图能够帮助你理解:
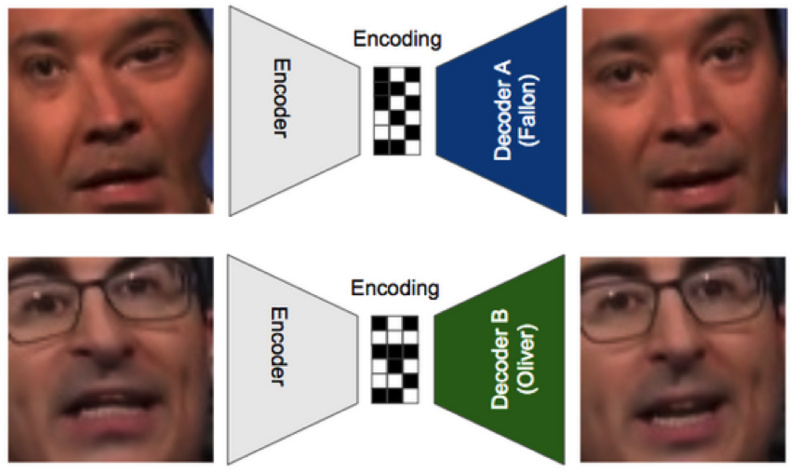
在这个案例中,使用的编码器是一样的,但是Fallon和Oliver的解码器是不同的。在训练的过程中,输入的人脸会被扭曲,从而模拟一个“我们希望得到这样的人脸”的概念。
下面我将介绍算法训练的三个步骤:
1. 首先,我们给编码器输入了一张Jimmy扭曲脸的图片,并尝试用解码器A来重新还原他的脸,这就使得解码器A必须要学会在纷繁复杂的图片中识别并且还原出Jimmy的脸。
2. 然后,把Oliver扭曲脸的图片输入至同一个编码器,并用解码器B来还原Oliver的脸。
3. 我们不断重复上面的操作,直到两个解码器能够分别还原出两个人的脸,同时编码器也能够学会通过抓取人脸关键信息,从而分辨出Jimmy和Oliver的脸。
等到以上的训练步骤都完成以后,我们就能把一张Jimmy的照片输入至编码器,然后直接把代码传输至解码器B,将Jimmy的脸换成Oliver的脸。

这就是我们通过训练模型完成换脸的全过程。解码器获取了Jimmy的脸部信息,然后把信息交给解码器B,这时候解码器B会作出这样的反应:“这又是一条干扰信息,这不是Oliver的脸,那么我就把你换成Oliver吧。”
一条算法仅通过观察许多图片就能够再次生成、还原这些图片,这听起来挺不可思议的,但DeepFakes确确实实做到了,而且效果还相当不错。
步骤是这样的
1:搜寻你要替换的AB两个人的头像,越多越好,工程里提供了脚本可以自动识别裁剪
2:训练样本,CPU执行太慢,GPU的话,tensorflow-gpu 依赖并行库,对显卡要求很高 <- 我卡在这里了
3:找你需要替换的视频,用ffmpeg提取成一帧一帧的图片
4:用你训练的样本对每一帧图片进行换脸
5:用ffmpeg 合成为视频关键是训练的模型,github工程附带的是神皇川普和烂片王凯奇的。
建议想自己动手丰衣足食的朋友 搞个VPS或者有一块好显卡。